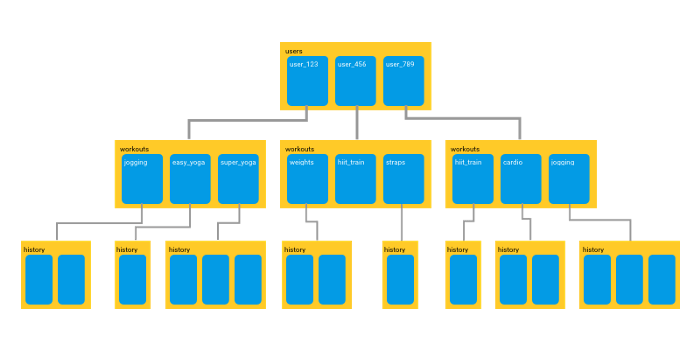
Trabalhando com Firestore: Construindo um modelo de banco de dados simples
Uma das perguntas mais frequentes no Stackoverflow ou em qualquer outra comunidade quando falamos sobre Firebase é como evitar consultas complexas ou aninhadas e como construir um modelo de banco de dados bom e simples. Esses dois conceitos andam juntos, porque se seu modelo for bom, é muito improvável que você precise de consultas aninhadas.
Este artigo fala sobre conceitos gerais a serem considerados no momento de construir nosso modelo de banco de dados para Firestore ou Realtime Database. Existem alguns conceitos e dicas que o ajudarão a mudar de idéia em relação ao modelo usual de bancos de dados relacionais com o qual estamos acostumados. Vamos começar com:
Conteudo
Evite dados profundos
{
"users": {
"user_id_1": {
"username": "user one",
"profile_pic": "some_url",
"articles": {
"article_id_1": {
"title": "Firebase is so cool",
"comments": {
"comment_id_1": "First comment",
"comment_id_2": "I like trains"
}
},
"article_id_2": {
"title": "Firestore rocks!",
"comments": {
"comment_id_1": "SQL it's better",
"comment_id_2": "Do you know the wae?"
}
}
}
}
}
}No código acima, podemos ver como a estrutura que estamos construindo está aninhando cada vez mais os modelos filho e qualquer um de seus atributos.
Isso faz com que nosso modelo cresça em tamanho e se torne impróprio para trabalhar nos casos em que não precisamos de todas as informações nele contidas. Por exemplo, se queremos os dados do usuário, as informações relacionadas com os artigos são desnecessárias. Nesse caso, normalizar nossa dabatase nos ajudará. O que significa normalizar? Bem, significa simplesmente separar nossas informações o máximo que pudermos:
{
"users": {
"user_id_1": {
"username": "user one",
"profile_pic": "some_url"
}
},
"articles": {
"article_id_1": {
"author": "user_id_1",
"title": "Firebase is so cool",
"comments": {
"comment_id_1": "First comment",
"comment_id_2": "I like trains"
}
}
}
}Fazendo isso, nossa estrutura fica achatada e seremos capazes de pegar os dados do user_id_1 sem recuperar nenhum dado relacionado com os artigos ou vice-versa.
Neste exemplo, também podemos separar comments de articles, movendo-os para uma subcoleção que nos leva à nossa próxima pergunta:
Quando devo aninhar uma coleção no Firestore?
Existem muitos casos em que podemos pensar em criar uma coleção dentro de um documento, ou talvez apenas usar um array ou mapa para manter uma lista de dados em nosso documento atual. Antes disso, temos que nos fazer algumas perguntas:
- Estes dados estão associados ao documento pai?
Temos que verificar se existe uma relação direta entre existe uma relação direta entre os dois. Os comentários de um artigo, curtidas ou compartilhamentos de uma postagem …
- Quero mostrar esses dados junto com os dados dos pais?
Se você deseja manter os dados separados nos modelos na hora de exibi-los. Lembre-se de que você pode tornar seu modelo mais leve movendo esses dados para uma coleção. Pense em uma publicação do Facebook, onde você vê o texto que seu amigo postou, mas apenas se ao clicar nos comentários, os comentários associados à publicação forem exibidos.
- Minha lista vai crescer muito?
Se quiser aninhar algumas dezenas ou centenas de objetos em seu POJO, você pode mantê-lo dentro de um array. Basta levar em consideração que seu modelo vai crescer e ficar pesado para baixar no cliente. Isso é muito importante porque os documentos do Firestore não podem ultrapassar 1 MB.
- E se eu quiser baixar apenas parcialmente os dados aninhados?
Mova os dados diretamente para uma coleção. É a única maneira de limitar o número de documentos recuperados.
- Algum dos meus parâmetros precisa acionar um Cloud Function?
Pode haver casos em que você não precisa salvar seus dados em uma coleção, mas deseja que os dados acionem uma Firestore Cloud Function. Mover esses dados para uma coleção é o movimento certo porque você poderá ser mais seletivo com os documentos que acionam o Cloud Function.
Quando gostaríamos de fazer isso? Bem, um bom exemplo será o momento em que queremos atualizar vários caminhos em nosso banco de dados ao mesmo tempo de forma atômica. Um exemplo poderia ser atualizar dados duplicados em nosso banco de dados … Dados duplicados em meu banco de dados! Esse cara é louco!
Dados duplicados são uma prática comum ao trabalhar com bancos de dados não relacionais como Firebase. Isso nos poupa de realizar consultas extras para obter dados, tornando a recuperação de dados mais rápida e fácil. Pense em nosso modelo atual acima, se quisermos mostrar os dados relacionados ao autor de um artigo, precisaríamos fazer uma consulta extra. Agora pense em uma lista na qual deseja mostrar muitos artigos. isso significa muitas consultas extras para recuperar os dados do autor. Vamos consertar:
{
"users": {
"user_id_1": {
"username": "user one",
"profile_pic": "some_url"
}
},
"articles": {
"article_id_1": {
"author": {
"id": "user_id_1",
"username": "user one",
"profile_pic": "some_url"
},
"title": "Firebase is so cool",
"comments": {
"comment_id_1": "First comment",
"comment_id_2": "I like trains"
}
}
}
}Podemos observar que todo artigo possui um objeto denominado autor que contém todos os dados relativos ao usuário. Da mesma forma, poderíamos fazer isso com os comentários se quisermos mostrar a foto do perfil e o nome do autor do comentário em nosso aplicativo. Para esses cenários, vamos falar sobre o próximo ponto do artigo: Atomicidade
Atomicidade
O que é atomicidade? Wikipedia explica isso melhor do que eu:
Uma transação atômica é uma série indivisível e irredutível de operações de banco de dados de tal forma que todas ocorrem ou nada ocorre.
Uma garantia de atomicidade evita que as atualizações no banco de dados ocorram apenas parcialmente, o que pode causar problemas maiores do que rejeitar toda a série de uma vez
As operações atômicas nos garantem que os dados que duplicamos em nosso modelo sejam atualizados ao mesmo tempo, todos de uma vez, evitando possíveis inconsistências. Isso geralmente é feito usando Cloud Functions trabalhando no servidor ou WriteBatches trabalhando no cliente.
Em ambos os casos, manter a atomicidade implica na implementação de algumas mudanças em nosso modelo. No modelo acima. Como poderíamos saber quais artigos foram escritos para um usuário? ou quais comentários foram escritos pelo usuário? Teremos que fazer muitas consultas ao longo de todo o banco de dados para obter os IDs dos artigos e comentários relacionados ao nosso usuário. Isso seria muito trabalho e perda de tempo.
É por isso que mantemos caminhos de relação em nossos modelos para fazer atualizações de vários caminhos
Atualizações de caminho de relação e multi-caminho
{
"users": {
"user_id_1": {
"username": "user one",
"profile_pic": "some_url",
"article_counter" : 2,
"author_of_articules": [
"article_id_1",
"article_id_2"
],
"author_of_comments": [
"comment_id_1"
]
},
"user_id_2": {
"username": "user two",
"profile_pic": "some_url_2",
"author_of_comments": [
"comment_id_2"
]
}
},
"articles": {
"article_id_1": {
"author": {
"id": "user_id_1",
"username": "user one",
"profile_pic": "some_url"
},
"title": "Firebase is so cool",
"comments": {
"comment_id_1": {
"comment": "First comment",
"author": {
"id": "user_id_1",
"username": "user one",
"profile_pic": "some_url"
}
},
"comment_id_2": "I like trains",
"author": {
"id": "user_id_2",
"username": "two",
"profile_pic": "some_url_2"
}
}
}
}
}Mantendo os IDs e dados necessários dos artigos e comentários feitos por um usuário, podemos acessar facilmente todos eles de uma vez e executar com a operação atômica em todos os caminhos, permitindo-nos modificar o nome de usuário e a foto do perfil em todo o nosso modelo.
Neste exemplo, você pode salvar o ID do artigo em authorOfComments. Isso permitirá que você crie toda a consulta:
articles/{articleId}/comments/{commentId}
Dica: Uma boa prática caso você precise de alguma meta-informação sobre a coleção é adicionar um campo extra e atualizá-lo de acordo com uma função de nuvem. Contagem de itens, hora da última atualização … são exemplos perfeitos para este caso de uso.
Você também pode encontrar muitas informações sobre a construção de bancos de dados não relacionais na web, se estiver interessado. Recomendo enfaticamente a leitura do artigo Técnicas de modelagem de dados NoSQL de Ilya Katsov, que você pode encontrar aqui.
O que devo fazer se ainda precisar de consultas aninhadas?
Serviços baseados em gráficos, como redes sociais, são bastante comuns hoje em dia. Nesses serviços, pequenos pedaços de informação, como o status de seguir/deixar de seguir, os usuários atualizam milhares de registros duplicados que afetam as informações aninhadas.
Queremos evitar esses cenários de todas as maneiras possíveis. Vou mostrar algumas técnicas que podem ser úteis para esses casos com o exemplo a seguir.
Nosso objetivo é mostrar os artigos de um usuário como parte de um feed que é composto por todos os artigos feitos por cada usuário na lista a seguir.
Isso não é possível com o Firestore porque não podemos consultar dados usando uma consulta de banco de dados tradicional como um where complexo com vários valores. Precisamos extrair o feed em uma nova coleção associada ao usuário. Esta coleção conterá duplicatas de todas as postagens que desejamos exibir:
{
"users": {
"user_id_1": {
"username": "user one",
"profile_pic": "some_url",
"feed": [
// Lista de postagens de todos os usuários que eu sigo
]
}
}
}A duplicação resolve o problema neste caso. Precisamos apenas fazer uma única consulta sobre {userId}/feed.
No entanto, com esse tipo de duplicação, podemos introduzir um novo conjunto de problemas. Vamos imaginar que você segue Lady Gaga no Twitter e precisa copiar para seu feed os 2 milhões de tweets que ela postou nos últimos anos. Você copia informações que podem nunca ser vistas pelo usuário. De maneira semelhante, sempre que Lady Gaga editar um tweet, uma atualização será necessária para cada seguidor. Isso se tornaria um grande gargalo.
Existem alguns casos em que normalizar nossas informações e fazer algumas consultas extras não é uma abordagem ruim. Se você encontrar esse caso em seu modelo de dados, pode aplicar algumas boas práticas para melhorar o desempenho:
- Evite copiar 100% das informações. A duplicação dos dados dos últimos 1-3 meses é o suficiente para esses casos.
- Avalie suas informações quando quiser atualizar dados de vários lugares. Por exemplo, atualize os dados dos usuários que estiveram ativos durante o último mês. O resto pode ser atualizado com algumas funções do Cloud ou processo em lote durante a noite.
- Normalize o banco de dados para esse caso se seus dados forem modificados várias vezes. Mantenha os IDs para fazer consultas individuais e o carimbo de data / hora para indexá-lo. É melhor fazer 100 consultas individualizadas para carregar os dados do usuário do que atualizá-los milhares de vezes cada vez que uma postagem é editada.
- Considere o uso de outros tipos de banco de dados se seu modelo se tornar muito complexo.
O Firebase é incrível, mas nem sempre é a melhor solução.
Você pode encontrar um exemplo das boas práticas e técnicas explicadas no artigo usando Firebase Firestore Cloud Functions em minha conta do Github: https://github.com/FrangSierra/firestore-cloud-functions-typescript
Espero que considere este artigo útil e, como sempre, qualquer feedback é muito bem-vindo.

























 com ZMPT101B e ESP8266 12E com Android App / Adafruit IO MQTT")


{kind=link}